Introduction
Recently I was asked once again to build out Kubernetes cluster infrastructure, and deploy and configure supporting software, and then migrate a client’s QA environment and applications to the cluster. This was all to be completed in a week or two. At this point in time, and with the tooling available, this request is fairly straightforward to architect and implement for a small company. However, when reflecting upon the path for this most recent request, I remembered the first time I performed this task almost four years ago. At that point (e.g., it was using EKS one week after exiting beta) and with the tooling available, the request was very stressful and was successful with little time to spare. It seemed interesting to note the many advances and improvements that have occurred from then until now to facilitate this type of migration and transformation.
In this article, we will explore a quick migration of a QA environment to Kubernetes for two small companies. One occurred in early 2018 and the other in early 2022. We will see some [hopefully] interesting differences between the two due to the time gap. Although the NDA with both clients is very relaxed (one publicly publishes and discusses all of the work performed, and the other has all of my delivered code available publicly on GitHub), we will refrain from any specific details that would divulge the identity of either company or any trade secrets thereof. The first company will be referred to as “Shades”, and the second company as “Pirates”.
Requirements and Architecture
Shades
Shades required a Kubernetes cluster to deploy deep learning batch jobs in a pseudo-serverless execution architecture. Kubeless was still new at the time as opposed to now abandoned, and FaaSnetes was also more proof of concept than proven at this juncture in time. The base image for the batch jobs was refactored into a multi-stage Docker build based on Alpine Python. This concept was also still fairly new at the time, although historically the high-level architectural concept of a multi-stage build has existed since Linux package management. The cluster needed to be prepared, provisioned, configured, and then the batch jobs deployed onto it. This should all be streamlined through an interface in a pipeline. Although these requirements seem few in retrospect, one should remember the tooling ecosystem and its low level of maturity as it existed at the time.
Pirates
Pirates required a Kubernetes cluster to deploy their stateless microservices. The Kubernetes cluster required proper interfacing with Consul and Vault server clusters for service mesh and secrets management. The cluster needed a proper ingress controller (the standard tool for this being Traefik, and it was selected here), and some method for interfacing this controller with AWS infrastructure. The applications needed to all properly interact with the supporting software. The applications all need to be deployed through a common mechanism and interface. The base images for the applications already existed, were mostly optimized and already were published to a container image artifact registry through pipelines. Compared to Shades, these requirements were significantly more involved and intricate. However, the maturity of the tooling ecosystem has almost matched the requirements of the environment. Also, Pirates had the advantage of being better equipped for this journey due to the later historical time.
Infrastructure
Shades
One should recall that it was only in early 2018 that Kubernetes won the container orchestration battles. Prior to that, there were multiple options competing (pause quickly for fun to see how many you can recall), and the space had not yet transformed into the competition for the best Kubernetes managed service offering. AWS eventually joined the arena with their EKS offering, and for reasons that I simply cannot recall (or perhaps blocked from memory), we decided to roll with that days after it exited beta.
Thankfully a savior had recently developed a Terraform module to provision EKS: terraform-aws-eks. Otherwise, it is unclear how we would ever have made any initial progress toward infrastructure provisioning. Experienced EKS users are very likely familiar with this offering, but it was completely new at the time. We can dust off the history book and look at the snippet of the module declaration:
```terraform
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 1.0"
#config_output_path = "~/.kube"
cluster_name = "${var.cluster_name}"
cluster_version = "1.10"
#subnets = "${concat(module.vpc.private_subnets, module.vpc.public_subnets)}"
kubeconfig_aws_authenticator_env_variables = {
AWS_PROFILE = "${var.aws_profile}"
}
subnets = "${module.vpc.private_subnets}"
tags = "${local.tags}"
vpc_id = "${module.vpc.vpc_id}"
worker_groups = "${local.worker_groups}"
worker_sg_ingress_from_port = "<port>"
}
```
A blast from the past. I do recall that I could not actually declare version 1.0.0 of this module until I upgraded to the somewhat recently released Terraform 0.11 and utilized its new features. That was also the second minor version of Terraform, where the providers were separated from the core for those who are interested historically.
The Terraform provider for Kubernetes was still community maintained at this time, and had issues interacting cleanly with the Kubernetes API. We only used it to provision an extra storage class for the cluster. The persistent volumes from this storage class stored the data for the stateless batch jobs.
Pirates
Of course, by February 2022 the tooling ecosystem was very much different. Kubernetes had acquired a lot of maturity, and Terraform had transitioned from industry standard by default (“the only game in town” as Kurt Vonnegut would say) to industry standard by all benchmarks. The Kubernetes provider transitioned to Hashicorp ownership and improved slowly but steadily. We also selected EKS for Pirates, but this was a significantly saner decision since EKS was now the plurality of managed service offerings for Kubernetes. Also, Pirates already had a significant presence in AWS, but this would be the first “platform vendor specific” software they leveraged.
```terraformmodule "eks" { source = "terraform-aws-modules/eks/aws" version = "~> 17.24" cluster_endpoint_private_access = true cluster_endpoint_public_access = true cluster_name = var.eks_configuration.name cluster_version = var.eks_configuration.version enable_irsa = true map_users = local.eks_map_users subnets = var.dedicated_vpc ? module.vpc.public_subnets["this"] : [for subnet in aws_subnet.eks : subnet.id] tags = { "Name" = "eks-${var.eks_configuration.name}" } vpc_id = var.dedicated_vpc ? module.vpc["this"].vpc_id : data.aws_vpc.this["this"].id worker_additional_security_group_ids = [aws_security_group.hashi.id] worker_groups = var.eks_configuration.worker_groups # use aws cli for auth kubeconfig_aws_authenticator_command = "aws" kubeconfig_aws_authenticator_command_args = [ "eks", "get-token", "--cluster-name", var.eks_configuration.name ]}```
A wonderful breath of fresh air comes alongside the enhanced feature set of modern tooling. For this infrastructure provisioning, the Kubernetes provider was also locked in at version 2.3.2 to enable simultaneous provisioning and not workaround with consecutive subset resource targeting.
The Terraform root module config here also deployed the AWS Load Balancer controller and output a rendered template Helm input values file for later deployment with the associated Helm chart for AWS LB. By this point in time, Terraform made complex and sophisticated EKS deployments and management almost trivial. In retrospect, it is easy to observe why one can possess so much more confidence in delivering this task today versus four years ago.
Software
Shades
Looking back at the Ansible role for provisioning the environment prior to the Terraform execution is a fun reminder of what life was like before the prevalence of containerized build agents:
```ansible- name: install from a static binary block: - name: download kubectl binary get_url: url: https://storage.googleapis.com/kubernetes-release/release/v/bin//amd64/kubectl dest: /usr/bin/kubectl - name: make kubectl executable file: state: file path: /usr/bin/kubectl mode: 0755 when: kubectl_pkg == false become: true```
Package management tasks were in there too as an option. It is also fun to recall how we had to do EKS authentication at first (good old iam-auth binary):
```- name: download heptio authenticator aws binary get_url: url: https://github.com/kubernetes-sigs/aws-iam-authenticator/releases/download/v/heptio-authenticator-aws___amd64 dest: /usr/bin/heptio-authenticator-aws become: true- name: make heptio authenticator aws executable file: state: file path: /usr/bin/heptio-authenticator-aws mode: 0755 become: true```
Ansible module support for Kubernetes at the time was such that we basically needed to do kubectl commands directly. Proper API interfacing with Ansible modules was still very much in preview at the time and was still enduring growing pains. The Kubernetes Python bindings still needed to be fully utilized for the Ansible modules.
```ansible- name: create gp2 storage class command: kubectl --context create -f storage-class.yaml when: default_storage.stdout !~ default```
Does everyone remember our good friend Tiller?
```ansible- name: initialize helm and install and configure tiller block: - name: check for tiller service account command: kubectl --context get sa --selector=.metadata.name=tiller ignore_errors: true register: tiller_account - name: create tiller service account and cluster bindings command: kubectl --context create -f rbac-config.yaml when: tiller_account.stdout !~ "tiller" - name: initialize helm and install/configure tiller command: helm init --wait --kube-context --service-account tiller when: tiller == "install"```
We were all really excited when Helm 3 went Tiller-less.
Pirates
Hooray for modern API bindings interactions and containerized build agents. The AWS Load Balancer Controller, Traefik, Vault, and Consul were all configured on the cluster through the Ansible tasks with native modules. These could also be transposed into a pipeline, given their highly imperative nature. Idempotence would be lost, but perhaps not at such a measurable cost.
```ansible- name: render consul values file ansible.builtin.template: src: "/templates/consul-values.j2" dest: "/files/consul-values.yaml" delegate_to: localhost- name: install consul client and connect service mesh kubernetes.core.helm: name: consul chart_ref: hashicorp/consul chart_version: "" release_namespace: consul-system create_namespace: true values_files: - "/files/consul-values.yaml" context: ""- name: manage consul gossip encryption key secret kubernetes.core.k8s: definition: apiVersion: v1 kind: Secret metadata: name: gossip-encryption namespace: consul-system data: key: ""```
I need to pause here for a moment to reflect on the Consul and Vault architecture. Both the Consul and Vault server clusters were external to the EKS cluster, but the Consul connect, and Vault Secrets sidecar injectors were within the clusters. The actual requirements for creating the backing pseudo-operators for these init containers to communicate with the external clusters had to be assembled from multiple source locations, including locations that were not even remotely documentation. Some of the requirements were also completely non-intuitive. Implementing both of those configurations successfully was a valuable experience in the sense that once you finish, then you actually have a sense of how to repeat that process in another cluster. Hopefully, one-day complete documentation will also exist for these procedures.
Applications
Shades
After developing the Helm chart for the pseudo-serverless batch jobs to execute on the Kubernetes cluster, everything was tied together neatly in a Jenkins Pipeline. The stages executed the pre-eks Ansible playbook, Terraform root module config, post-eks Ansible playbook, and the Helm deployment. These all used the Jenkins Pipeline libraries and plugins of the time. We can see a snippet of Helm installing the Kubernetes dashboard.
```groovystage('Deploy Kubernetes Dashboard') { environment { KUBECONFIG = "${env.WORKSPACE}/kubeconfig" } steps { print 'Install Dashboard with Helm Chart' script { helm.install { chart = 'stable/kubernetes-dashboard' name = 'kube-dash' namespace = 'kube-system' set = ['rbac.clusterAdminRole=true'], } } } post { success { print 'Kubernetes Dashboard deployed successfully.' } failure { print 'Failure deploying kubernetes Dashboard.' } }}```
Check out that classic DSL indeed for the Jenkins Pipeline library for Helm.
Pirates
The Helm chart for deploying the Pirates’ microservices included a clusterrolebinding for Vault, configmap for config files, deployment, hpa, ingress for Traefik, service (and extra service account to satisfy an obscure Consul connect injector sidecar requirement), serviceaccount, and traefikroute for the ingress.
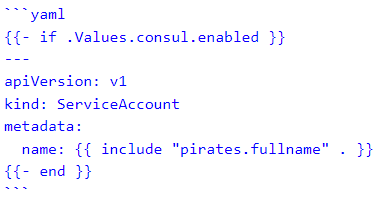
Secret Consul sidecar and external server requirements!
I am excited for Sprig to develop further functionality for Helm chart templating. Namespacing and scoping is still a bit awkward, but the iterables and enumerables are rather solid. I would hope that one day the templating engine achieves feature parity with engines like ERB and Jinja2 where the derivative languages (Ruby and Python) can essentially be almost embedded in the code.

Conclusion
Revisiting the migration from several years ago and comparing it to a recent migration was an interesting journey through time (for myself, at least). It helped me to realize how much better the tooling and ecosystem are today, and how much more difficult this kind of effort was in the past. It is also worth noting that there are still use cases and configurations that have not been fully vetted by the community and industry quite yet, and as such, the tooling support for them is not fully mature. It will, therefore perhaps be interesting to see how all of this continues to change in the next several years gradually, and then to maybe revisit the delta again.
If your organization is interested in customized Kubernetes migrations of your existing environments, infrastructure, and applications, then contact Shadow-Soft.